Interrogez une IA générique sur votre entreprise et vous obtiendrez des conseils génériques. L'écart n'est pas l'intelligence — c'est le contexte.
Tout dirigeant qui a collé une question d'affaires dans un outil public l'a vécu : plausible, fluide, faux pour votre réalité. Les textes précédents de cette série portaient sur le contexte dans chaque prompt et les pratiques d'équipe. Celui-ci monte d'un cran : fenêtres de contexte, recherche (RAG) et vos propres données — la couche qui transforme l'IA en outil opérationnel.
En bref
- Fenêtre de contexte = quantité de texte (mesurée en tokens, unités de texte) que le modèle « voit » par requête — avec des limites réelles
- RAG (génération augmentée par recherche) = récupérer des documents pertinents de votre corpus, puis générer une réponse
- Sans données curatées, l'IA devine à partir de l'entraînement public — risqué pour les opérations et la conformité
- La stratégie de contexte rejoint gouvernance et sécurité
Pourquoi les fenêtres de contexte comptent
Les LLM (grands modèles de langage) traitent un volume fini par appel — politiques, courriels, manuels, historique de conversation. Au-delà, quelque chose est tronqué — souvent silencieusement.
| Symptôme | Cause probable |
|---|---|
| Réponse ignore une partie du téléversement | Troncature |
| Réponses incohérentes le même jour | Morceaux différents récupérés |
| « Oublie » les instructions du début | Fenêtre pleine |
Règle pratique : envoyer ce qui compte pour cette tâche, pas tout ce que vous possédez. Résumer le long ; pointer vers les sources canoniques. Un gestionnaire qui colle 80 pages de notes de projet et demande une synthèse direction obtient souvent un résumé qui ignore la section budgétaire — pas parce que le modèle est « bête », mais parce que la fenêtre est saturée.
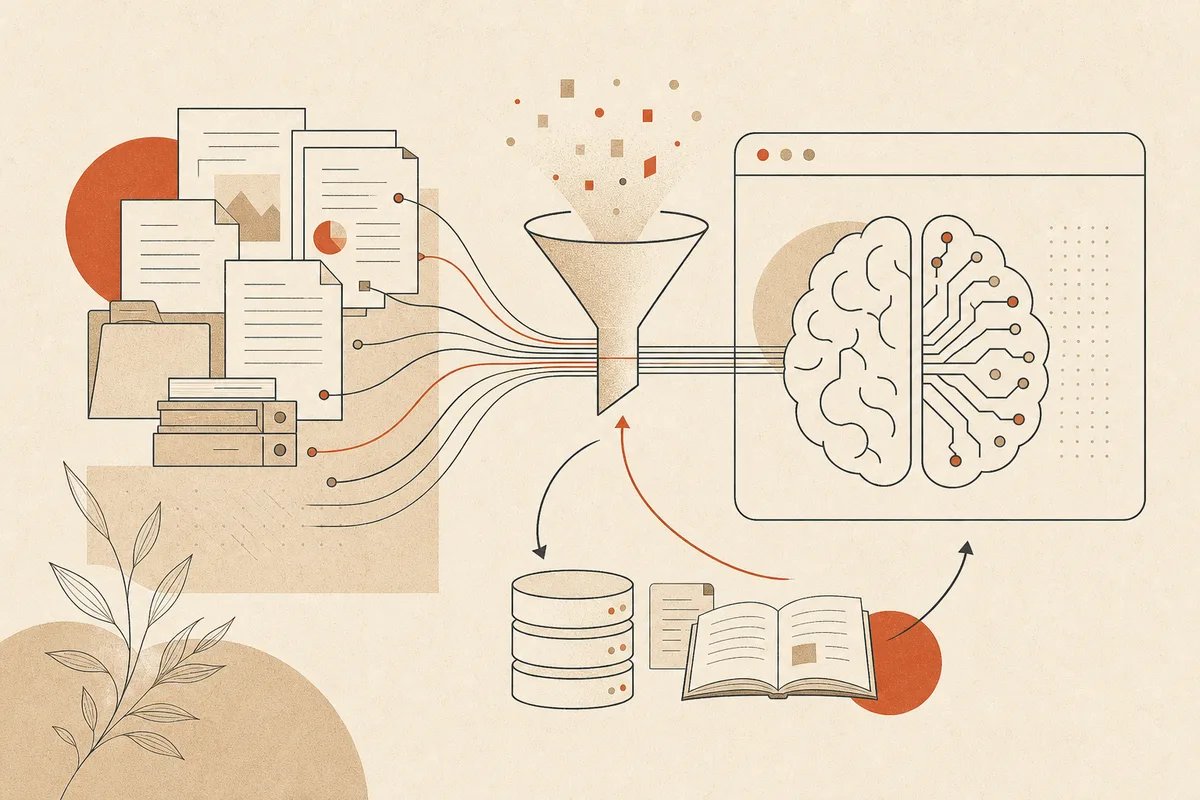
Le RAG en langage clair
La génération augmentée par recherche (RAG) suit quatre étapes :
- L'utilisateur pose une question
- Le système cherche dans la base approuvée (politiques, wiki, projets)
- Les passages pertinents sont injectés dans le prompt
- Le modèle répond — idéalement avec citations
Bien fait, l'IA passe de « inconnu brillant » à « collègue briefé ». Mal fait, elle cite avec assurance la mauvaise politique — souvent une version obsolète encore indexée.
Construire le corpus est du travail opérationnel, pas un projet IT en vase clos. Le texte 8 de cette série détaille comment bâtir une base de connaissances.
Données d'affaires : actif et risque
Vos données expliquent la valeur spécifique :
- Historique de prix, SOP, propositions passées, résolutions de tickets
- Archives de réunions, gabarits d'inspection, listes réglementaires
D'où l'importance de confidentialité. Classifier avant indexation :
- Vert — interne, faible sensibilité, bon pour un RAG initial
- Jaune — personnel ou confidentiel — accès strict et journalisation
- Rouge — exclu jusqu'avis juridique et sécurité
Ne jamais indexer « tout le lecteur » en v1. Le bruit noie le signal — et multiplie les risques.
Un cabinet que j'ai conseillé a indexé les politiques RH avant les SOP opérationnelles — mauvaise priorité pour son pilote. Le personnel posait des questions terrain ; le système renvoyait des extraits sur les vacances. Réordonner le corpus autour des 30 questions hebdomadaires a corrigé la qualité plus vite qu'un changement de modèle.
Contexte pour agents et flux
Les agents autonomes multiplient les besoins — CRM, courriel, outils en une seule exécution. Sans :
- Source de vérité par type de donnée
- Permissions alignées sur les rôles humains
- Journalisation des récupérations
…les agents amplifient la confusion plus vite que le clavardage. Le contexte système n'est pas optionnel quand l'IA agit, pas seulement quand elle répond.
Améliorer le contexte sans gros projet
- Un dossier ou wiki canonique pour le domaine pilote
- Retirer doublons et versions obsolètes — le RAG déteste les PDF périmés
- Métadonnées — propriétaire, date, langue (fr/en), statut
- 20 questions réelles que l'équipe pose chaque semaine ; noter la qualité des réponses
- Boucle de retour — « mauvais doc récupéré » = signal produit, pas erreur utilisateur
Contexte et prompt ensemble
Même avec RAG, de bons prompts précisent :
- Quelles sources privilégier
- Que faire si preuve absente (« dire que vous ne savez pas »)
- Format et points à valider en relecture
« Utiliser seulement les documents fournis » est un minimum — il faut l'appliquer dans la conception du flux, pas l'espérer.
Où vous en êtes
Vous avez standardisé les pratiques de prompt d'équipe ; ce texte explique pourquoi vos données et votre historique comptent plus que le modèle du jour. Prochaine étape : IA multimodale : texte, audio, images et vidéo — cas d'usage opérationnels au-delà du texte seul.
Avant d'acheter un autre outil de clavardage, Échangeons. On vérifiera si vos données sont prêtes pour le RAG — ou ce qu'il faut corriger d'abord.